At CES, Nvidia just announced at Project Digits which is branded as your “personal AI Super Computer.” What makes this interesting:
128GB of memory is enough to run 70B models. That can open up some new experimentation options.
You can link a couple of these together to run even larger models. This is the technique used for data center shizzle, so bringing this to the desktop is cool.
The Nvidia stack. Having access to the Blackwell architecture is sweet, but the secret sauce is the software stack, specifically CUDA. This is really Nvidia’s moat that gives them the competitive advantage. Build against this, and you can run on any of Nvidia’s stuff from the edge on up to hyperscale data centers.
If you are a software engineer, IMO it’s worth investing some $ in this type of hardware vs. spinning up cloud instances to learn. Why? There are things you can do locally on your own network that allow you to experiment/learn faster than in the cloud. For instance, video feeds are very high bandwidth that are easier to experiment with locally than pushing that feed to the cloud (and all the security that goes with exposing outside your firewall.)
I bought a few Nvidia Jetson devices to use around the house and experiment with. I went with these vs. a discrete GPU + desktop machine because of power consumption: A desktop machine + GPU will use 300W+, and these Jetson edge devices use 10-50W.
I normally experiment with machine learning & AI shizzle using either a Jupyter notebook or a python IDE. But in this demo, I decided to check out Agent Studio. You fire up the container image, open up the link in your browser, and start dragging/dropping shizzle on to the canvas. Seriously rapid experimentation.
The video source is an RSTP video feed from my security camera.
The video output also produces an RSTP video feed. Not shown in the demo but I also experimented with overlaying the LLM output (tokens) with the video source to produce an LLM augmented video feed showing what it “saw”
This feeds into a multimodal LLM with a prompt of “describe the image concisely.”
I wire up the output to a text-to-speech model. Since video/LLM is operating in a constant loop, I also experiment with wiring up a deduping node.
This demo allowed my to get an idea of how these bits perform. I was interested in tokens/sec, memory utilization, and CPU/GPU utilization. Next, I plan to build out an Agentic AI solution architecture for my home security.
Some think we’re in an AI bubble where AI is being over-hyped. Massive data centers are being built specifically for AI hardware (aka NVIDIA). Power consumption is so extreme that Big Tech wants to go nuclear.
Gen-ai is good at extracting context from unstructured data. This is a game changer.
There is a ton of investment $$$ flowing into this space. This will impact how we build software and what/how users interact with computers. This is very much like the previous Dot Com boom where the Internet/Ecommerce would fundamental change commerce… it was just the huge investments were too early for the “other” technical changes needed to make ecommerce ubiquitous: mobile phones and cheap networking.
Data centers and hyper-scale are needed for some workflows, but you can’t overcome physics and the round-trip latency of data transfer, which makes true interactive multimodal interactions challenging.
AI at the Edge is where I think the future is headed. We will want to use our phone or tablet with multi-modal gen-ai to assist us with “things.” This requires low-latency. For example, the speech-to-text models running on your phone performing real-time transcription of a voice mail is immensely useful to avoid spam calls.
According to Jensen Huang’s keynote, the future of programming is tokens. You feed tokens around to different “AI’s” that are specialized in a particular domain. This is the basis for Agentic AI.
I’ve seen shifts in tech and the software industry over my career. Historically, it has been about higher and higher level of abstractions:
Assembly abstracted machine op codes. C/C++ abstracted assembly.
Managed languages abstracted unmanaged languages which conversely abstracted the host CPU and hardware architecture (write once/run anywhere).
Operating systems abstracted the computer hardware
Databases abstracted the file system
Sockets abstracted the network.
But in each one of those abstractions, you still wrote code to sequence all that shizzle. It was deterministic logic based on discrete math. Now, in this new gen-ai world you decompose your domain into tokens. And within this domain, you have sub-domains that are specialized/optimized AIs. Each one of these gen-ai domains produces a probabilistic result based on linear algebra and statistics. Basically, it is a very smart guesstimate.
So now, tokens are abstracting the programming languages. And the holy grail everyone is chasing is Artificial General Intelligence (AGI) where the AI can do its own planning/reasoning. This abstracts out the programming language because the computer can figure out its own shizzle.
If you are a software engineer, you will absolutely need to add these tools to your toolkit. And I am not talking about just using a gen-ai API LLM wrapper. You really should dig behind that LLM API wrapper and:
Learn how machine learning models are created and build your own “hello world” model. You could build the Not Hotdog App and become the next tech unicorn.
Let’s use microk8s for kubernetes to host pihole + DNS over HTTPs (DoH). A few years ago, I hit my limit on the Internet advertising. You know, you do a search for something, and then all of a sudden you’re getting presented with all these personalized ads for that thing… everywhere you go. So I fired up a docker container to “try out” pihole on my raspberry pi. It was quick and it worked.
My next evolution was to prevent my ISP (or anyone on the Net) from sniffing my DNS traffic. I used CloudFlared as an HTTPS tunnel/proxy to the CloudFlare 1.1.1.1 DNS servers (they do not log traffic.) Then I wired up pihole to proxy its upstream DNS to use this CloudFlared tunnel. I put all of this into a docker-compose file and that “just worked.”
Over time, I spun up other things such as influxdb, grafana, home-assistant, ads/b tracking, jellyfin, and a bunch of other things. All on various raspberry pi’s hosting docker instances. It was getting… messy.
I’ve now standardized on using Microk8s for container orchestration and management mixed with git-ops for infrastructure automation.
I see a lot of “here’s how you configure pihole” to run as a docker container, but there isn’t much out there for using microk8s. Here’s my contribution.
MicroK8s for our kubernetes container orchestration and management
For microk8s, make sure the following add-ons are enabled:
dns
ingress
metallb
MetalLb is a load balancer that allows us to assign a fixed ip address “in front of” our k8 pods. K8 will handle the mapping to the proper node (for clusters) and pod. We just use the assigned load balancer ip.
Follow the tutorial and make note of whatever ip address pool you assign to metallb. It should be an unused range on your network (i.e. outside of any DHCP scope or other statically assigned addresses.)
Setting up the pi-hole application in Microk8s (k8)
kubectl apply -f pihole-namespace.yml
Best practice is to use K8 namespaces to segment up your cluster resources. Our first step is to create our pihole namespace
When the pod hosting our pihole container is running it will need disk storage. My k8 is setup to use a NFS server for storage. If you are using host-path or just want ephemeral storage, edit the file and replace nfs-csi with “” (a quoted empty string)
adlists.list is used during the very first bootstrapping to populate the gravity database with the domains to blacklist.
custom.list is used for local dns entries. For instance, if you get tired of remembering various ip addresses on your network, you can make an entry in this file to map the ip address to a fully-qualified-domain-name.
We are going to use a k8 feature called a ConfigMap. Later, we will “volumeMount” these configMaps into the pod’s filesystem. Run the helper scripts. If you get an error about not finding the kubectl command, just copy the command from the script file and run in your terminal window.
This step creates a “deployment.” We’re gonna spin up two containers in the pod:
Cloudflared – this creates our HTTPs tunnel to the CloudFlare 1.1.1.1 DNS servers
Pihole – this will become our network DNS server
Because both of these containers live in a pod, we can share address space. The pihole environment variable DNS points to 127.0.0.1#5053 which is the port we’ve setup Cloudflared to use.
kubectl apply -f pihole-deployment.yaml
If your deployment step was successful, pihole should be running
kubectl get pod -n pihole
The last step is to create a service to allow the outside world to interact/connect to our pihole pod. Pihole will be used as the DNS server for your network, so it’s important to use a static/fixed ip address. Select an available ip address in your metallb load balancer address space. Then edit this file and replace the xxx.xxx.xxx.xxx with the correct ip address.
kubectl apply -f pihole-service.yml
If the service installed successfully, you should be able to login to your pihole instance using the loadbalancer ip address you selected in the previous step. The default password is ‘nojunk’ (set in the pihole-deployment.yml file) http://xxx.xxx.xxx.xxx/admin
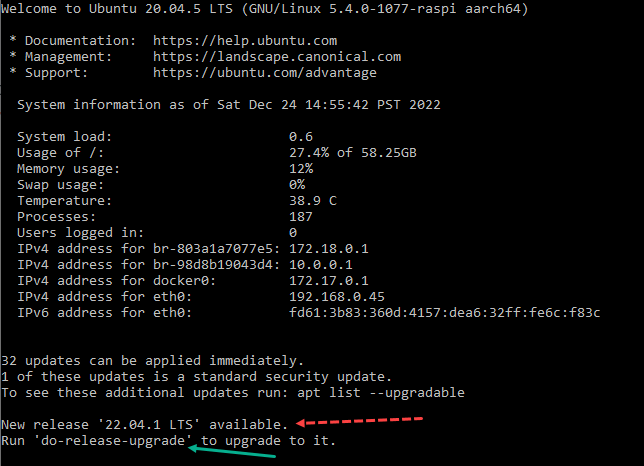
tl;dr: ubuntu 22.04 jammy jellyfish needs vxlan capability to support microk8s.
# after installing ubuntu 22.04 jammy jellyfish (or upgrading) run
sudo apt install linux-modules-extra-5.15.0-1005-raspi linux-modules-extra-raspi
I cut my teeth typing assembly language listings out of Byte magazine; overclocking used to involve unsoldering and replacing the crystal on the motherboard; operating system distribution used to come on multiple floppies. I’ve put in my dues to earn my GreyBeard status.
I have learned two undeniable truths:
Always favor clean OS installs vs. in-place upgrades
Don’t change a lot of shit all at once
Every time I was logging into one of the cluster nodes, I’d see this
terminal view after logging in to a microk8 node
I’ve been kicking the “ops” can down the road but I had some free time, so let’s break rule #1 and run sudo do-release-upgrade. Ubuntu has generally been good to me (i.e. it just works), so there shouldn’t be any problems. And there wasn’t. The in-place upgrade was successful across all the nodes.
Well that was easy. Might as well break rule #2 and also upgrade microk8s to the latest/stable version (currently 1.26). My microk8s version was too old to go directly to the latest version, so no biggie I’ll just rebuild the cluster.
sudo snap remove microk8s
sudo snap install microk8s --classic --channel=latest/stable
microk8s add-node
# copy/paste the shizzle from the add-node to the target node to join, etc.
And that is when shit when south. Damn, I broke my rules and got called on it.
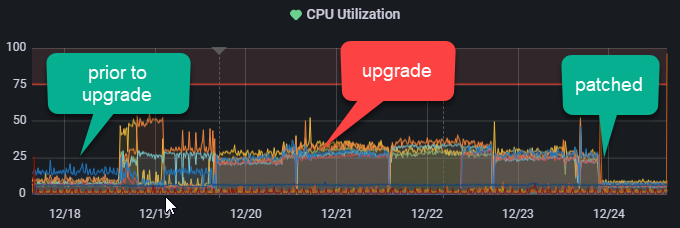
Cluster dns wasn’t resolving. I was getting metrics-server timeouts. And the cluster utilization was higher than normal which I attributed to cluster sync overhead.
CPU behavior change – pre vs. post upgrade. Note behavior after patch applied
I went deep down the rabbit hole. I was focused on dns because without that, nothing would work. I used the kubernetes debugging dns resolution and tried various microk8 configurations. Everything was fine with a single node. But in a cluster configuration nothing seemed to work.
For my home network, I use pihole and I have my own dns A records for stuff on my network. So I also went down the path of reconfiguring core-dns to use /etc/resolve.conf and/or point it at my pihole instance. That was also a bust.
I also enabled metallb and this should have been my “ah ha!” On a single node, I could assign a loadbalancer ip address. But in a cluster, nope. This is all layer 2 type stuff.
Lots of google-fu, and I stumble across Portainer Namespace Issue. I was also using Portainer to troublehsoot. Portainer on a single node worked fine. But Portainer in a cluster could not enumerate the namespaces (cluster operation). But I see this post by @allardkrings:
the difference of my setup with yours is that I am running the kubernetes cluster on 3 physycal raspberry PI nodes. I did some googling and found out that on the Raspberry PI running Ubuntu 22.04 the VXLAN module is not loaded by default. Running sudo apt install linux-modules-extra-5.15.0-1005-raspi linux-modules-extra-raspi solved the problem.
That caught my eye, and clicking on the issue linked to that post made it click. I was also seeing high CPU utilization, metallb was jacked (layer 2), etc.
After installing those packages and rebuilding the microk8 cluster, everything “just works.”
Woke up today to some microk8 cluster unhappiness. Some auto upgrades caused my leo-ntp-monitoring app to stop. I’ve been lazy and using Portainer as a UI vs remembering all the kubectl command line shizzle. When I tried to pull up Portainer in the browser, it was giving me some message about “Portainer has been upgraded, please restart Portainer to reset the security context” or something like that.
Well shit. I don’t even have a cup of coffee in me and I gotta start using my brain. Here’s the shell script to restart Portainer.
I’ve been running a few docker workloads on various stand-alone raspberry pi 4 hosts. This has worked well, but I decided to up my game a bit and setup a Kubernetes cluster. Why? Kubernetes is the container orchestration technology that is taking over the cloud and figured it would be a good learning opportunity to figure out how all the bits play together.
For my workloads, I need a 64 bit OS and I am using raspberry pi 4 8GB boards with a power-over-ethernet (POE) hat. I am using Ubuntu Server 64 bit and I am using Microk8s for the Kubernetes runtime. The tutorials are straight forward and I am not going to rehash that, but instead call out the gotchas to look out for.
CoreDNS
For my infrastructure stuff, I use DHCP reservations with long leases and make an internal DNS entries. This is a lot easier to centrally manage that doing static address assignments. I knew I was going to need k8 DNS support, so I did the following….
microk8s enable dns
And then when I moved my docker hosted container into a pod it failed. After a little troubleshooting to make sure there wasn’t any network layer issues, and validating that I could resolve external DNS names, I knew the problem was CoreDNS wasn’t pointed at my internal DNS servers. There are a couple ways to fix this…
# pass the dns server ips when enabling coredns
microk8s enable dns:dns1, dns2
# or you can edit the configuration after-the-fact
microk8s kubectl -n kube-system edit configmap/coredns
Private Registry
I wanted to run a private registry to start with. Why? ISP connections can fail and it is also a fast way for me to experiment. Microk8s is the container orchestration layer, and it is using Docker for the container runtime. Docker by default will attempt to use HTTPs when connecting to the registry, which breaks with the private registry. You will see an error such as “…http: server gave HTTP response to HTTPS client.”
I am running a 3 node cluster, and I setup the registry storage on node-01. So we have to make some configuration edits…
# edit the docker /etc/docker/daemon.json file and add the ip address or FQDN to the registry host. I did this on each node of the cluster
{
"insecure-registries" : ["xx.xx.xx.xx:32000"]
}
# restart docker
sudo systemclt restart docker
# now edit the container template and use the same
# ip address/FQDN. I did this step on each node in
# the cluster to make sure everything was consistent.
# The point of a cluster is to let the cluster consider
# all resources when picking a host, so each node needs
# to be able to pull the docker images if there is a
# redeployment, scaling event, etc.
sudo nano /var/snap/microk8s/current/args/containerd-template.toml
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."xx.xx.xx.xx:32000"]
endpoint = ["http://xx.xx.xx.xx:32000"]
# after making the edit/saving, restart the microk8s node
microk8s stop
microk8s start
I ported the leo ntp time server monitoring to run in the microk8s cluster. It has worked flawlessly until it croaked. The entire cluster was jacked up. I was using channel=1.20/stable which was the latest release at that time. I have since rebuilt the cluster to use channel=1.21/stable and everything has been bullet proof.
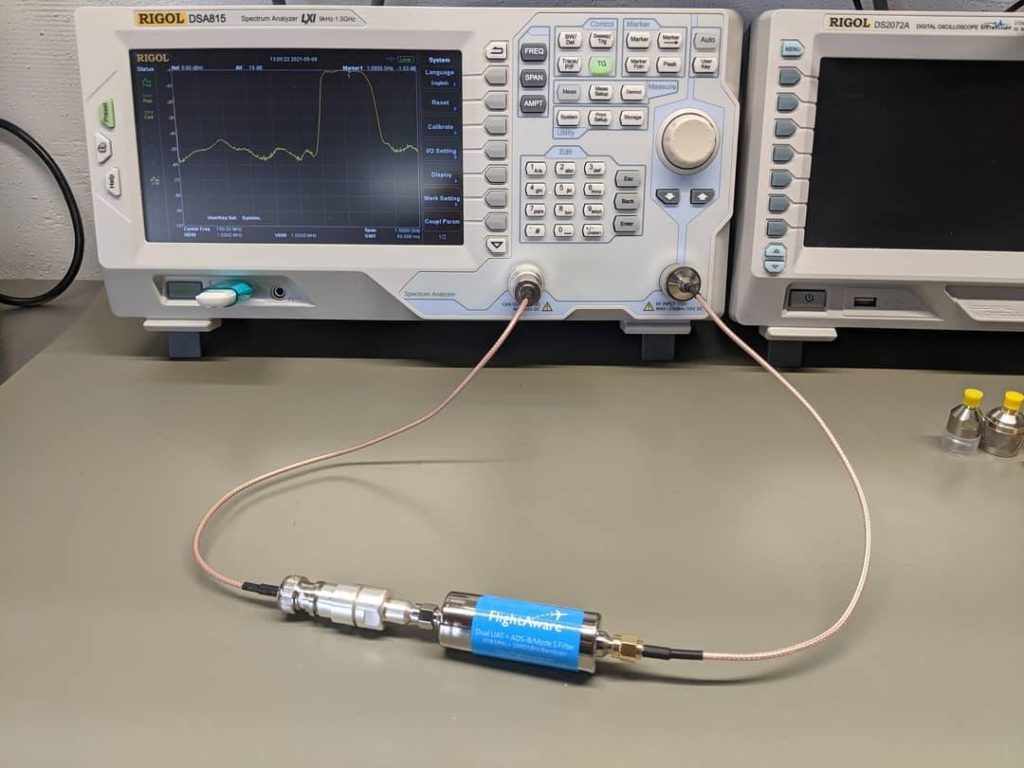
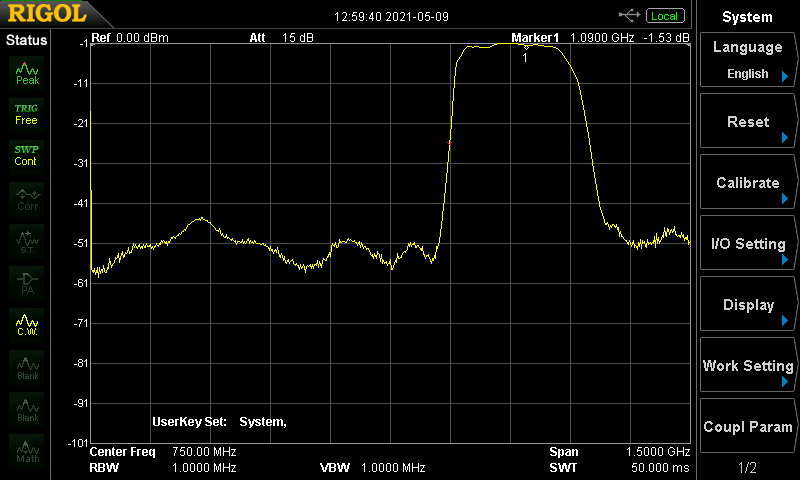
I plan to build an ADS-B tracker. However, I live in an RF noisy urban neighborhood, and all that noise can desense an RF receiver, so I bought this FlightAware Dual UAT+ADS-B filter. I put it on the spectrum analyzer and I measured a passband from ~930Mhz to ~1.2Ghz with ~1.5dB of insertion loss. Since this is all up in the gighertz range, my plan is to keep the antenna feedlines short by mounting a raspberry pi 4 in a weather-rated enclosure close to the antenna. I’ll power all of it by running a network cable with POE to the raspberry pi with a POE hat.
This little device uses the GPS satellite’s atomic clock to provide a highly accurate stratum-1 time source to your network. Wouldn’t it be great if you can pull metrics from it so you can monitor performance? Then you might want to checkout the monitoring shizzle I built. It runs in a docker container and feeds time series data to InfluxDB.
Prisoner’s Dilemma comes from game theory. Essentially, two prisoners are not allowed to collaborate, and then are presented a set of options: stay silent and get a guaranteed sentence, or cooperate and get immunity. The optimal solution is to stay silent.
What does this have to do with Corona Virus and Covid-19? Right now, the only effective way to mitigate the spread of the virus is through social distancing: staying away from others to slow the spread. But humans can become irrational in time of panic – really toilet paper?
Corona Virus is now a pandemic and we now have a prisoner’s dilemma problem at a global scale – in absence of a cure/vaccine, the only other way to get this virus to go away would be to blunt the transmission: 7 billion people go on lock down/isolation for ~3 weeks. Otherwise, once people start moving around again (travel, random social contact, etc.) you will just get more flare ups. This isn’t feasible.
What’s not the solution? Self-interest. If you pursue your own self interests, and everyone pursues their own self interests – i.e. everyone goes Mad Max Thunder Dome, that puts excessive demand on supply chains and the health care systems. This will feed panic, which can turn to social unrest, and a bunch of other shitty outcomes.
What is a solution? Cooperation. What does cooperation look like? Practice social distancing. Don’t horde. Help your neighbors and the less fortunate. Maintain your physical and mental health.
Prisoner’s Dilemma. Accept the fact that this Corona Virus pandemic will affect you either directly or indirectly. You will not come out unscathed. The optimal solution for society will be cooperation not individualism.